


вЛЁЂШБЪЇЪ§ОнЕФВњЩњЛњжЦ
дкГщбљЕїВщжаЃЌОГЃЛсгіЕНЕїВщЮЪОэжаФГаЉЯюФПУЛгаЛиД№ЕФЧщПіЃЌетОЭЪЧЪ§ОнШБЪЇЕФЮЪЬтЁЃЪ§ОнШБЪЇЮЪЬтЮоТлЪЧдкЪаГЁЕїВщЁЂеўИЎЕїВщЛЙЪЧбЇЪѕЕїВщжаЖМГЪЯждНРДдНбЯжиЕФЧїЪЦЁЃетЪЧгЩЖржждвђдьГЩЕФЁЃЪзЯШЃЌЙЋУёдНРДдНжиЪгИіШЫЕФвўЫНШЈЃЌВЛдИвтЭИТЖвЛаЉИіШЫаХЯЂЃЛЦфДЮЃЌВЛЙцЗЖЕФЪаГЁЕїВщгАЯьСЫЕїВщЕФбЯЫрадЃЌЪЙЕУЪмЗУепЖдИїРрЕїВщВЛаМвЛЙЫЃЌВЛФмШЯецЖдД§ЃЛЕкШ§ЃЌЮЪОэЩшМЦВЛЙцЗЖЃЌЮЪОэФкШнЙ§ГЄЛђЙ§ФбЃЌгШЦфЪЧЪаГЁЕїВщжаЕФИїРр“ДюГЕЕїВщ”ЪЙЕУЮЪОэЙ§ГЄЃЌдьГЩЪмЗУепЕФбсОыаФРэЃЛЕкЫФЃЌЕїВщжїАьЕЅЮЛВЛжиЪгЗУЮЪдБЕФХрбЕЃЌЗУЮЪдБШБЗІвЛаЉБиБИЕФзЗЮЪЁЂВЙЮЪЁЂВщТЉЕШЛљБОММЧЩЁЃ
ШБЪЇЪ§ОнИљОнЦфВњЩњЛњжЦПЩвдЗжЮЊЭъШЋЫцЛњШБЪЇЃЈMCARЃЉЁЂЫцЛњШБЪЇЃЈMARЃЉКЭЗЧЫцЛњШБЪЇЃЈMNARЃЉЁЃЭъШЋЫцЛњШБЪЇЪЧжИетбљвЛжжЧщПіЃКШБЪЇЧщПіЯрЖдгкЫљгаПЩЙлВтКЭВЛПЩЙлВтЕФЪ§ОнРДЫЕЃЌдкЭГМЦбЇвтвхЩЯЪЧЖРСЂЕФЁЃБШШчЫЕЃЌЪмЗУепдкНжЭЗНгЪмЗУЮЪЪБЃЌЭЛШЛЩГСЃДЕНјСЫблОІЕМжТЮЪОэКѓУцЕФЮЪЬтЮоЗЈЛиД№ЃЌДгЖјдьГЩСЫЪ§ОнШБЪЇЁЃЫцЛњШБЪЇЪЧвЛИіЙлВтГіЯжШБЪЇжЕЕФИХТЪЪЧгЩЪ§ОнМЏжаВЛКЌШБЪЇжЕЕФБфСПОіЖЈЕФЃЌЖјВЛЪЧгЩКЌШБЪЇжЕЕФБфСПОіЖЈЕФЁЃЗЧЫцЛњШБЪЇЪЧгыШБЪЇЪ§ОнБОЩэДцдкФГжжЙиСЊЃЌБШШчЮЪЬтЩшМЦЙ§гкУєИадьГЩЕФШБЪЇЁЃ
ЪЖБ№ШБЪЇЪ§ОнЕФВњЩњЛњжЦЪЧМЋЦфживЊЕФЁЃЪзЯШетЩцМАЕНДњБэадЮЪЬтЁЃДгЭГМЦЩЯЫЕЃЌЗЧЫцЛњШБЪЇЕФЪ§ОнЛсВњЩњгаЦЋЙРМЦЃЌвђДЫВЛФмКмКУЕиДњБэзмЬхЁЃЦфДЮЃЌЫќОіЖЈЪ§ОнВхВЙЗНЗЈЕФбЁдёЁЃЫцЛњШБЪЇЪ§ОнДІРэЯрЖдБШНЯМђЕЅЃЌЕЋЗЧЫцЛњШБЪЇЪ§ОнДІРэБШНЯРЇФбЃЌдвђдкгкЦЋВюЕФГЬЖШФбвдАбЮеЁЃ
ШБЪЇЪ§ОнЕФВхВЙЪЧжИбЁдёКЯРэЕФЪ§ОнДњЬцШБЪЇЪ§ОнЁЃВЛЭЌЕФВхВЙЗЈЖдзмЬхЭЦЖЯЛсВњЩњНЯДѓЕФгАЯьЃЌгШЦфЪЧдкШБЪЇЪ§СПНЯДѓЕФЧщПіЯТЁЃФПЧАЙњФкбЇепЖдШБЪЇЪ§ОнЕФВхВЙЮЪЬтЩаЮДгаГфЗжЕФШЯЪЖЁЃБЪепЗЂЯжЃЌбаОПепдкГщбљЕїВщБЈИцжаКмЩйЛсЫЕУїШБЪЇжЕЕФДІРэЗНЗЈЃЌЕЋЪТЪЕЩЯЃЌОјДѓВПЗжЩчЛсПЦбЇЕїВщЃЈАќРЈЪаГЁЕїВщЃЉЖМЛсАќКЌВЛЭъећЕФЪ§ОнЃЌРэгІЖдДЫгаЫљЫЕУїЁЃ
ЖўЁЂМИжжГЃМћЕФШБЪЇЪ§ОнВхВЙЗНЗЈ
ЃЈвЛЃЉИіАИЬоГ§ЗЈ(Listwise Deletion)
зюГЃМћЁЂзюМђЕЅЕФДІРэШБЪЇЪ§ОнЕФЗНЗЈЪЧгУИіАИЬоГ§ЗЈ(listwise deletion)ЃЌвВЪЧКмЖрЭГМЦШэМўЃЈШчSPSSКЭSASЃЉФЌШЯЕФШБЪЇжЕДІРэЗНЗЈЁЃдкетжжЗНЗЈжаШчЙћШЮКЮвЛИіБфСПКЌгаШБЪЇЪ§ОнЕФЛАЃЌОЭАбЯрЖдгІЕФИіАИДгЗжЮіжаЬоГ§ЁЃШчЙћШБЪЇжЕЫљеМБШР§БШНЯаЁЕФЛАЃЌетвЛЗНЗЈЪЎЗжгааЇЁЃжСгкОпЬхЖрДѓЕФШБЪЇБШР§ЫуЪЧ“аЁ”БШР§ЃЌзЈМвУЧвтМћвВДцдкНЯДѓЕФВюОрЁЃгабЇепШЯЮЊгІдк5%вдЯТЃЌвВгабЇепШЯЮЊ20%вдЯТМДПЩЁЃШЛЖјЃЌетжжЗНЗЈШДгаКмДѓЕФОжЯоадЁЃЫќЪЧвдМѕЩйбљБОСПРДЛЛШЁаХЯЂЕФЭъБИЃЌЛсдьГЩзЪдДЕФДѓСПРЫЗбЃЌЖЊЦњСЫДѓСПвўВидкетаЉЖдЯѓжаЕФаХЯЂЁЃдкбљБОСПНЯаЁЕФЧщПіЯТЃЌЩОГ§ЩйСПЖдЯѓОЭзувдбЯжигАЯьЕНЪ§ОнЕФПЭЙладКЭНсЙћЕФе§ШЗадЁЃвђДЫЃЌЕБШБЪЇЪ§ОнЫљеМБШР§НЯДѓЃЌЬиБ№ЪЧЕБШБЪ§ОнЗЧЫцЛњЗжВМЪБЃЌетжжЗНЗЈПЩФмЕМжТЪ§ОнЗЂЩњЦЋРыЃЌДгЖјЕУГіДэЮѓЕФНсТлЁЃ
ЃЈЖўЃЉОљжЕЬцЛЛЗЈ(Mean Imputation)
дкБфСПЪЎЗжживЊЖјЫљШБЪЇЕФЪ§ОнСПгжНЯЮЊХгДѓЕФЪБКђЃЌИіАИЬоГ§ЗЈОЭгіЕНСЫРЇФбЃЌвђЮЊаэЖргагУЕФЪ§ОнвВЭЌЪББЛЬоГ§ЁЃЮЇШЦзХетвЛЮЪЬтЃЌбаОПепГЂЪдСЫИїжжИїбљЕФАьЗЈЁЃЦфжаЕФвЛИіЗНЗЈЪЧОљжЕЬцЛЛЗЈ(mean imputation)ЁЃЮвУЧНЋБфСПЕФЪєадЗжЮЊЪ§жЕаЭКЭЗЧЪ§жЕаЭРДЗжБ№НјааДІРэЁЃШчЙћШБЪЇжЕЪЧЪ§жЕаЭЕФЃЌОЭИљОнИУБфСПдкЦфЫћЫљгаЖдЯѓЕФШЁжЕЕФЦНОљжЕРДЬюГфИУШБЪЇЕФБфСПжЕЃЛШчЙћШБЪЇжЕЪЧЗЧЪ§жЕаЭЕФЃЌОЭИљОнЭГМЦбЇжаЕФжкЪ§дРэЃЌгУИУБфСПдкЦфЫћЫљгаЖдЯѓЕФШЁжЕДЮЪ§зюЖрЕФжЕРДВЙЦыИУШБЪЇЕФБфСПжЕЁЃЕЋетжжЗНЗЈЛсВњЩњгаЦЋЙРМЦЃЌЫљвдВЂВЛБЛЭЦГчЁЃОљжЕЬцЛЛЗЈвВЪЧвЛжжМђБуЁЂПьЫйЕФШБЪЇЪ§ОнДІРэЗНЗЈЁЃЪЙгУОљжЕЬцЛЛЗЈВхВЙШБЪЇЪ§ОнЃЌЖдИУБфСПЕФОљжЕЙРМЦВЛЛсВњЩњгАЯьЁЃЕЋетжжЗНЗЈЪЧНЈСЂдкЭъШЋЫцЛњШБЪЇЃЈMCARЃЉЕФМйЩшжЎЩЯЕФЃЌЖјЧвЛсдьГЩБфСПЕФЗНВюКЭБъзМВюБфаЁЁЃ
ЃЈШ§ЃЉШШПЈЬюГфЗЈЃЈHotdeckingЃЉ
ЖдгквЛИіАќКЌШБЪЇжЕЕФБфСПЃЌШШПЈЬюГфЗЈдкЪ§ОнПтжаевЕНвЛИігыЫќзюЯрЫЦЕФЖдЯѓЃЌШЛКѓгУетИіЯрЫЦЖдЯѓЕФжЕРДНјааЬюГфЁЃВЛЭЌЕФЮЪЬтПЩФмЛсбЁгУВЛЭЌЕФБъзМРДЖдЯрЫЦНјааХаЖЈЁЃзюГЃМћЕФЪЧЪЙгУЯрЙиЯЕЪ§ОиеѓРДШЗЖЈФФИіБфСПЃЈШчБфСПYЃЉгыШБЪЇжЕЫљдкБфСПЃЈШчБфСПXЃЉзюЯрЙиЁЃШЛКѓАбЫљгаИіАИАДYЕФШЁжЕДѓаЁНјааХХађЁЃФЧУДБфСПXЕФШБЪЇжЕОЭПЩвдгУХХдкШБЪЇжЕЧАЕФФЧИіИіАИЕФЪ§ОнРДДњЬцСЫЁЃгыОљжЕЬцЛЛЗЈЯрБШЃЌРћгУШШПЈЬюГфЗЈВхВЙЪ§ОнКѓЃЌЦфБфСПЕФБъзМВюгыВхВЙЧАБШНЯНгНќЁЃЕЋдкЛиЙщЗНГЬжаЃЌЪЙгУШШПЈЬюГфЗЈШнвзЪЙЕУЛиЙщЗНГЬЕФЮѓВюдіДѓЃЌВЮЪ§ЙРМЦБфЕУВЛЮШЖЈЃЌЖјЧветжжЗНЗЈЪЙгУВЛБуЃЌБШНЯКФЪБЁЃ
ЃЈЫФЃЉЛиЙщЬцЛЛЗЈ(Regression Imputation)
ЛиЙщЬцЛЛЗЈЪзЯШашвЊбЁдёШєИЩИідЄВтШБЪЇжЕЕФздБфСПЃЌШЛКѓНЈСЂЛиЙщЗНГЬЙРМЦШБЪЇжЕЃЌМДгУШБЪЇЪ§ОнЕФЬѕМўЦкЭћжЕЖдШБЪЇжЕНјааЬцЛЛЁЃгыЧАЪіМИжжВхВЙЗНЗЈБШНЯЃЌИУЗНЗЈРћгУСЫЪ§ОнПтжаОЁСПЖрЕФаХЯЂЃЌЖјЧввЛаЉЭГМЦШэМўЃЈШчStataЃЉвВвбОФмЙЛжБНгжДааИУЙІФмЁЃЕЋИУЗНЗЈвВгажюЖрБзЖЫЃЌЕквЛЃЌетЫфШЛЪЧвЛИіЮоЦЋЙРМЦЃЌЕЋЪЧШДШнвзКіЪгЫцЛњЮѓВюЃЌЕЭЙРБъзМВюКЭЦфЫћЮДжЊаджЪЕФВтСПжЕЃЌЖјЧветвЛЮЪЬтЛсЫцзХШБЪЇаХЯЂЕФдіЖрЖјБфЕУИќМгбЯжиЁЃЕкЖўЃЌбаОПепБиаыМйЩшДцдкШБЪЇжЕЫљдкЕФБфСПгыЦфЫћБфСПДцдкЯпадЙиЯЕЃЌКмЖрЪБКђетжжЙиЯЕЪЧВЛДцдкЕФЁЃ
ЃЈЮхЃЉЖржиЬцДњЗЈ(Multiple Imputation)
ЖржиЙРЫуЪЧгЩRubinЕШШЫгк1987ФъНЈСЂЦ№РДЕФвЛжжЪ§ОнРЉГфКЭЭГМЦЗжЮіЗНЗЈЃЌзїЮЊМђЕЅЙРЫуЕФИФНјВњЮяЁЃЪзЯШЃЌЖржиЙРЫуММЪѕгУвЛЯЕСаПЩФмЕФжЕРДЬцЛЛУПвЛИіШБЪЇжЕЃЌвдЗДгГБЛЬцЛЛЕФШБЪЇЪ§ОнЕФВЛШЗЖЈадЁЃШЛКѓЃЌгУБъзМЕФЭГМЦЗжЮіЙ§ГЬЖдЖрДЮЬцЛЛКѓВњЩњЕФШєИЩИіЪ§ОнМЏНјааЗжЮіЁЃзюКѓЃЌАбРДздгкИїИіЪ§ОнМЏЕФЭГМЦНсЙћНјаазлКЯЃЌЕУЕНзмЬхВЮЪ§ЕФЙРМЦжЕЁЃгЩгкЖржиЙРЫуММЪѕВЂВЛЪЧгУЕЅвЛЕФжЕРДЬцЛЛШБЪЇжЕЃЌЖјЪЧЪдЭМВњЩњШБЪЇжЕЕФвЛИіЫцЛњбљБОЃЌетжжЗНЗЈЗДгГГіСЫгЩгкЪ§ОнШБЪЇЖјЕМжТЕФВЛШЗЖЈадЃЌФмЙЛВњЩњИќМггааЇЕФЭГМЦЭЦЖЯЁЃНсКЯетжжЗНЗЈЃЌбаОПепПЩвдБШНЯШнвзЕиЃЌдкВЛЩсЦњШЮКЮЪ§ОнЕФЧщПіЯТЖдШБЪЇЪ§ОнЕФЮДжЊаджЪНјааЭЦЖЯЁЃNORMЭГМЦШэМўПЩвдНЯЮЊМђБуЕиВйзїИУЗНЗЈЃЈNORMЭГМЦШэМўПЩвддкhttp://www.stat.psu.edu/~jls/misoftwa.htmlПЩвдУтЗбЯТдиЃЉЁЃ
Ш§ЁЂЮхжжВхВЙЗНЗЈЕФЪЕжЄБШНЯ
ЮЊСЫБШНЯетЮхжжШБЪЇжЕВхВЙЗНЗЈЕФВЛЭЌНсЙћЃЌЮвУЧЪЙгУЪЕМЪЪ§ОнПтНјааЪЕжЄбаОПЁЃЪ§ОнРДдДгкСуЕубаОПзЩбЏМЏЭХгк2006ФъЧяЖддЦФЯХЉДх169ЮЛХЉУёНјааЕФОгУёЩњЛюЕїВщЁЃЮвУЧвдДЫДЮЕїВщжаЩцМАЕНЕФ4ИіБфСПЮЊР§ЃКФъСфЁЂЪеШыЁЂОЋЩёЩњЛюТњвтЖШЁЂбЙСІИаЕУЗжЁЃЦфжаЃЌФъСфУЛгаШБЪЇжЕЁЃЪеШывд“ЧЇ”ЮЊЕЅЮЛЃЌга21%ЕФШБЪЇжЕЁЃОЋЩёЩњЛюТњвтЖШЮЊ6ЯюжИБъЕУЗжжЎКЭЃЌзмЗжЮЊ30ЗжЃЌга2%ЕФШБЪЇжЕЁЃбЙСІИаЕУЗжЃЈБОДЮЕїВщЕФвђБфСПЃЉЮЊ3ЯюжИБъЕУЗжжЎКЭЃЌзмЗжЮЊ15ЗжЃЌга16%ЕФШБЪЇжЕЁЃ
ЃЈвЛЃЉУшЪіаджИБъБШНЯ
ЮвУЧЪзЯШБШНЯВЩгУ5жжЗНЗЈВхВЙКѓЃЌУПИіБфСПЕФОљжЕКЭБъзМВюЕФБфЛЏЁЃГ§СЫдкИіАИЬоГ§ЗЈжага58ЮЛИіАИБЛЬоГ§жЎЭтЃЌЦфгр4жжЗНЗЈЖМга169ИіИіАИВЮгыМЦЫугыЗжЮіЁЃ
ДгБэ1жаПЩвдЗЂЯжВЩгУВЛЭЌЕФВхВЙЗНЗЈЃЌЦфБфСПЕФОљжЕКЭБъзМВюЪЧВЛЭЌЕФЁЃЕББфСПЕФШБЪЇжЕБШНЯЩйЪБЃЈШчОЋЩёЩњЛюТњвтЖШЃЉЃЌВЩгУ5жжЗНЗЈВхВЙКѓЕФОљжЕКЭБъзМВюВювьНЯаЁЁЃЕЋЕБШБЪЇжЕЫљеМБШР§діДѓЪБЃЈШчЪеШыЁЂбЙСІИаЕУЗжЃЉЃЌВЩгУВЛЭЌЗНЗЈКѓЕФОљжЕКЭБъзМВюВювьНЯДѓЁЃ5жжЗНЗЈжаЃЌЪЙгУИіАИЬоГ§ЗЈКѓИїБфСПЕФБъзМВюЖМУїЯддіДѓЃЌЪЙгУОљжЕЬцЛЛЗЈКѓИїБфСПЕФБъзМВюЖМУїЯдМѕаЁЁЃ
ЃЈЖўЃЉЛиЙщЗжЮіБШНЯ
ЮвУЧвдбЙСІИаЕУЗжЮЊвђБфСПЃЌЦфгр3ИіБфСПЮЊздБфСПНјааЛиЙщЗжЮіЁЃЙлВьБэ2ПЩвдЗЂЯжЃЌДгFжЕЩЯПДЃЌИіАИЬоГ§ЗЈгыЛиЙщЬцЛЛЗЈЕФFжЕНЯИпЁЃ
гЩгкЛиЙщЗжЮіжаЃЌИїИіБфСПЪЧЯрЛЅЙиСЊЕФЃЌЫљвдЫфШЛФъСфБфСПУЛгаШБЪЇжЕЃЌЕЋгЩгкЦфЫћБфСПДцдкШБЪЇЃЌЕМжТФъСфБфСПдкЛиЙщЗНГЬжаЕФЯЕЪ§вВЛсЗЂЩњБфЛЏЁЃДгБэ2жаПЩвдПДГіетжжБфЛЏЪЧБШНЯДѓЕФЃЌЦфжаTжЕДг-0.38БфЛЏжС1.01ЃЌгыжЎЯргІЕФPжЕвВДг0.314БфЛЏжС0.71ЁЃетЬсабЮвУЧЃЌдкНјааЖрдЊЗжЮіЪБЃЌгШЦфвЊзЂжиШБЪЇЪ§ОнВхВЙЗНЗЈЕФЪЙгУЃЌвђЮЊЫќВЛНіЛсгАЯьЕНгаШБЪЇжЕЕФБфСПЃЌЖјЧвгАЯьУЛгаШБЪЇжЕЕФБфСПЁЃ
ВЩгУВЛЭЌВхВЙЗНЗЈЖд“ЪеШы”БфСПЕФгАЯьНЯДѓЁЃЦфжаЃЌЪЙгУШШПЈЬюГфЗЈКѓЕФЯЕЪ§ЪЧзюДѓЕФЃЌВЂЧвУїЯдИпгкСЫВЩгУЦфЫћЗНЗЈВхВЙКѓЕФЯЕЪ§ЁЃДгPжЕЩЯПДЃЌЪЙгУШШПЈЬюГфЗЈИУБфСПЕФгАЯьВЛЪЧЯджјЕФЃЌЕЋЪЙгУЦфЫћВхВЙЗНЗЈЃЌШДПЩвдЪЙЕУИУБфСПЖдвђБфСПЕФгАЯьЪЧЯджјЕФЁЃетКЭЧАУцЕФЗжЮіЪЧвЛжТЕФЃЌМДдкЛиЙщЗжЮіжаЃЌгУШШПЈЬюГфЗЈЛёЕУЕФЯЕЪ§ЪЧВЛЮШЖЈВЛПЩППЕФЁЃ
гІИУЫЕЩЯЪі5жжШБЪЇжЕВхВЙЗНЗЈИїгаРћБзЃЌбаОПепдкбЁгУВхВЙЗНЗЈЪБгІИУзлКЯПМТЧШБЪЇЪ§ОнВњЩњЛњжЦЁЂШБЪЇжЕЫљеМБШР§ЁЂбаОПФмСІЁЂЪБМфЯожЦЕШвђЫиЃЌОпЬхЧщПіОпЬхЗжЮіЃЌбАевЕНдкЕБЧАЬѕМўЯТзюЪЪвЫЕФЗНЗЈЁЃЖдгкИїРрВхВЙЃЌЙВЭЌЕФФПЕФдкгкЪЙВЛЭъШЋбљБОЕФвбгааХЯЂЕУЕНзюМбРћгУЁЃ
дкГщбљЕїВщжаЃЌОГЃЛсгіЕНЕїВщЮЪОэжаФГаЉЯюФПУЛгаЛиД№ЕФЧщПіЃЌетОЭЪЧЪ§ОнШБЪЇЕФЮЪЬтЁЃЪ§ОнШБЪЇЮЪЬтЮоТлЪЧдкЪаГЁЕїВщЁЂеўИЎЕїВщЛЙЪЧбЇЪѕЕїВщжаЖМГЪЯждНРДдНбЯжиЕФЧїЪЦЁЃетЪЧгЩЖржждвђдьГЩЕФЁЃЪзЯШЃЌЙЋУёдНРДдНжиЪгИіШЫЕФвўЫНШЈЃЌВЛдИвтЭИТЖвЛаЉИіШЫаХЯЂЃЛЦфДЮЃЌВЛЙцЗЖЕФЪаГЁЕїВщгАЯьСЫЕїВщЕФбЯЫрадЃЌЪЙЕУЪмЗУепЖдИїРрЕїВщВЛаМвЛЙЫЃЌВЛФмШЯецЖдД§ЃЛЕкШ§ЃЌЮЪОэЩшМЦВЛЙцЗЖЃЌЮЪОэФкШнЙ§ГЄЛђЙ§ФбЃЌгШЦфЪЧЪаГЁЕїВщжаЕФИїРр“ДюГЕЕїВщ”ЪЙЕУЮЪОэЙ§ГЄЃЌдьГЩЪмЗУепЕФбсОыаФРэЃЛЕкЫФЃЌЕїВщжїАьЕЅЮЛВЛжиЪгЗУЮЪдБЕФХрбЕЃЌЗУЮЪдБШБЗІвЛаЉБиБИЕФзЗЮЪЁЂВЙЮЪЁЂВщТЉЕШЛљБОММЧЩЁЃ
ШБЪЇЪ§ОнИљОнЦфВњЩњЛњжЦПЩвдЗжЮЊЭъШЋЫцЛњШБЪЇЃЈMCARЃЉЁЂЫцЛњШБЪЇЃЈMARЃЉКЭЗЧЫцЛњШБЪЇЃЈMNARЃЉЁЃЭъШЋЫцЛњШБЪЇЪЧжИетбљвЛжжЧщПіЃКШБЪЇЧщПіЯрЖдгкЫљгаПЩЙлВтКЭВЛПЩЙлВтЕФЪ§ОнРДЫЕЃЌдкЭГМЦбЇвтвхЩЯЪЧЖРСЂЕФЁЃБШШчЫЕЃЌЪмЗУепдкНжЭЗНгЪмЗУЮЪЪБЃЌЭЛШЛЩГСЃДЕНјСЫблОІЕМжТЮЪОэКѓУцЕФЮЪЬтЮоЗЈЛиД№ЃЌДгЖјдьГЩСЫЪ§ОнШБЪЇЁЃЫцЛњШБЪЇЪЧвЛИіЙлВтГіЯжШБЪЇжЕЕФИХТЪЪЧгЩЪ§ОнМЏжаВЛКЌШБЪЇжЕЕФБфСПОіЖЈЕФЃЌЖјВЛЪЧгЩКЌШБЪЇжЕЕФБфСПОіЖЈЕФЁЃЗЧЫцЛњШБЪЇЪЧгыШБЪЇЪ§ОнБОЩэДцдкФГжжЙиСЊЃЌБШШчЮЪЬтЩшМЦЙ§гкУєИадьГЩЕФШБЪЇЁЃ
ЪЖБ№ШБЪЇЪ§ОнЕФВњЩњЛњжЦЪЧМЋЦфживЊЕФЁЃЪзЯШетЩцМАЕНДњБэадЮЪЬтЁЃДгЭГМЦЩЯЫЕЃЌЗЧЫцЛњШБЪЇЕФЪ§ОнЛсВњЩњгаЦЋЙРМЦЃЌвђДЫВЛФмКмКУЕиДњБэзмЬхЁЃЦфДЮЃЌЫќОіЖЈЪ§ОнВхВЙЗНЗЈЕФбЁдёЁЃЫцЛњШБЪЇЪ§ОнДІРэЯрЖдБШНЯМђЕЅЃЌЕЋЗЧЫцЛњШБЪЇЪ§ОнДІРэБШНЯРЇФбЃЌдвђдкгкЦЋВюЕФГЬЖШФбвдАбЮеЁЃ
ШБЪЇЪ§ОнЕФВхВЙЪЧжИбЁдёКЯРэЕФЪ§ОнДњЬцШБЪЇЪ§ОнЁЃВЛЭЌЕФВхВЙЗЈЖдзмЬхЭЦЖЯЛсВњЩњНЯДѓЕФгАЯьЃЌгШЦфЪЧдкШБЪЇЪ§СПНЯДѓЕФЧщПіЯТЁЃФПЧАЙњФкбЇепЖдШБЪЇЪ§ОнЕФВхВЙЮЪЬтЩаЮДгаГфЗжЕФШЯЪЖЁЃБЪепЗЂЯжЃЌбаОПепдкГщбљЕїВщБЈИцжаКмЩйЛсЫЕУїШБЪЇжЕЕФДІРэЗНЗЈЃЌЕЋЪТЪЕЩЯЃЌОјДѓВПЗжЩчЛсПЦбЇЕїВщЃЈАќРЈЪаГЁЕїВщЃЉЖМЛсАќКЌВЛЭъећЕФЪ§ОнЃЌРэгІЖдДЫгаЫљЫЕУїЁЃ
ЖўЁЂМИжжГЃМћЕФШБЪЇЪ§ОнВхВЙЗНЗЈ
ЃЈвЛЃЉИіАИЬоГ§ЗЈ(Listwise Deletion)
зюГЃМћЁЂзюМђЕЅЕФДІРэШБЪЇЪ§ОнЕФЗНЗЈЪЧгУИіАИЬоГ§ЗЈ(listwise deletion)ЃЌвВЪЧКмЖрЭГМЦШэМўЃЈШчSPSSКЭSASЃЉФЌШЯЕФШБЪЇжЕДІРэЗНЗЈЁЃдкетжжЗНЗЈжаШчЙћШЮКЮвЛИіБфСПКЌгаШБЪЇЪ§ОнЕФЛАЃЌОЭАбЯрЖдгІЕФИіАИДгЗжЮіжаЬоГ§ЁЃШчЙћШБЪЇжЕЫљеМБШР§БШНЯаЁЕФЛАЃЌетвЛЗНЗЈЪЎЗжгааЇЁЃжСгкОпЬхЖрДѓЕФШБЪЇБШР§ЫуЪЧ“аЁ”БШР§ЃЌзЈМвУЧвтМћвВДцдкНЯДѓЕФВюОрЁЃгабЇепШЯЮЊгІдк5%вдЯТЃЌвВгабЇепШЯЮЊ20%вдЯТМДПЩЁЃШЛЖјЃЌетжжЗНЗЈШДгаКмДѓЕФОжЯоадЁЃЫќЪЧвдМѕЩйбљБОСПРДЛЛШЁаХЯЂЕФЭъБИЃЌЛсдьГЩзЪдДЕФДѓСПРЫЗбЃЌЖЊЦњСЫДѓСПвўВидкетаЉЖдЯѓжаЕФаХЯЂЁЃдкбљБОСПНЯаЁЕФЧщПіЯТЃЌЩОГ§ЩйСПЖдЯѓОЭзувдбЯжигАЯьЕНЪ§ОнЕФПЭЙладКЭНсЙћЕФе§ШЗадЁЃвђДЫЃЌЕБШБЪЇЪ§ОнЫљеМБШР§НЯДѓЃЌЬиБ№ЪЧЕБШБЪ§ОнЗЧЫцЛњЗжВМЪБЃЌетжжЗНЗЈПЩФмЕМжТЪ§ОнЗЂЩњЦЋРыЃЌДгЖјЕУГіДэЮѓЕФНсТлЁЃ
ЃЈЖўЃЉОљжЕЬцЛЛЗЈ(Mean Imputation)
дкБфСПЪЎЗжживЊЖјЫљШБЪЇЕФЪ§ОнСПгжНЯЮЊХгДѓЕФЪБКђЃЌИіАИЬоГ§ЗЈОЭгіЕНСЫРЇФбЃЌвђЮЊаэЖргагУЕФЪ§ОнвВЭЌЪББЛЬоГ§ЁЃЮЇШЦзХетвЛЮЪЬтЃЌбаОПепГЂЪдСЫИїжжИїбљЕФАьЗЈЁЃЦфжаЕФвЛИіЗНЗЈЪЧОљжЕЬцЛЛЗЈ(mean imputation)ЁЃЮвУЧНЋБфСПЕФЪєадЗжЮЊЪ§жЕаЭКЭЗЧЪ§жЕаЭРДЗжБ№НјааДІРэЁЃШчЙћШБЪЇжЕЪЧЪ§жЕаЭЕФЃЌОЭИљОнИУБфСПдкЦфЫћЫљгаЖдЯѓЕФШЁжЕЕФЦНОљжЕРДЬюГфИУШБЪЇЕФБфСПжЕЃЛШчЙћШБЪЇжЕЪЧЗЧЪ§жЕаЭЕФЃЌОЭИљОнЭГМЦбЇжаЕФжкЪ§дРэЃЌгУИУБфСПдкЦфЫћЫљгаЖдЯѓЕФШЁжЕДЮЪ§зюЖрЕФжЕРДВЙЦыИУШБЪЇЕФБфСПжЕЁЃЕЋетжжЗНЗЈЛсВњЩњгаЦЋЙРМЦЃЌЫљвдВЂВЛБЛЭЦГчЁЃОљжЕЬцЛЛЗЈвВЪЧвЛжжМђБуЁЂПьЫйЕФШБЪЇЪ§ОнДІРэЗНЗЈЁЃЪЙгУОљжЕЬцЛЛЗЈВхВЙШБЪЇЪ§ОнЃЌЖдИУБфСПЕФОљжЕЙРМЦВЛЛсВњЩњгАЯьЁЃЕЋетжжЗНЗЈЪЧНЈСЂдкЭъШЋЫцЛњШБЪЇЃЈMCARЃЉЕФМйЩшжЎЩЯЕФЃЌЖјЧвЛсдьГЩБфСПЕФЗНВюКЭБъзМВюБфаЁЁЃ
ЃЈШ§ЃЉШШПЈЬюГфЗЈЃЈHotdeckingЃЉ
ЖдгквЛИіАќКЌШБЪЇжЕЕФБфСПЃЌШШПЈЬюГфЗЈдкЪ§ОнПтжаевЕНвЛИігыЫќзюЯрЫЦЕФЖдЯѓЃЌШЛКѓгУетИіЯрЫЦЖдЯѓЕФжЕРДНјааЬюГфЁЃВЛЭЌЕФЮЪЬтПЩФмЛсбЁгУВЛЭЌЕФБъзМРДЖдЯрЫЦНјааХаЖЈЁЃзюГЃМћЕФЪЧЪЙгУЯрЙиЯЕЪ§ОиеѓРДШЗЖЈФФИіБфСПЃЈШчБфСПYЃЉгыШБЪЇжЕЫљдкБфСПЃЈШчБфСПXЃЉзюЯрЙиЁЃШЛКѓАбЫљгаИіАИАДYЕФШЁжЕДѓаЁНјааХХађЁЃФЧУДБфСПXЕФШБЪЇжЕОЭПЩвдгУХХдкШБЪЇжЕЧАЕФФЧИіИіАИЕФЪ§ОнРДДњЬцСЫЁЃгыОљжЕЬцЛЛЗЈЯрБШЃЌРћгУШШПЈЬюГфЗЈВхВЙЪ§ОнКѓЃЌЦфБфСПЕФБъзМВюгыВхВЙЧАБШНЯНгНќЁЃЕЋдкЛиЙщЗНГЬжаЃЌЪЙгУШШПЈЬюГфЗЈШнвзЪЙЕУЛиЙщЗНГЬЕФЮѓВюдіДѓЃЌВЮЪ§ЙРМЦБфЕУВЛЮШЖЈЃЌЖјЧветжжЗНЗЈЪЙгУВЛБуЃЌБШНЯКФЪБЁЃ
ЃЈЫФЃЉЛиЙщЬцЛЛЗЈ(Regression Imputation)
ЛиЙщЬцЛЛЗЈЪзЯШашвЊбЁдёШєИЩИідЄВтШБЪЇжЕЕФздБфСПЃЌШЛКѓНЈСЂЛиЙщЗНГЬЙРМЦШБЪЇжЕЃЌМДгУШБЪЇЪ§ОнЕФЬѕМўЦкЭћжЕЖдШБЪЇжЕНјааЬцЛЛЁЃгыЧАЪіМИжжВхВЙЗНЗЈБШНЯЃЌИУЗНЗЈРћгУСЫЪ§ОнПтжаОЁСПЖрЕФаХЯЂЃЌЖјЧввЛаЉЭГМЦШэМўЃЈШчStataЃЉвВвбОФмЙЛжБНгжДааИУЙІФмЁЃЕЋИУЗНЗЈвВгажюЖрБзЖЫЃЌЕквЛЃЌетЫфШЛЪЧвЛИіЮоЦЋЙРМЦЃЌЕЋЪЧШДШнвзКіЪгЫцЛњЮѓВюЃЌЕЭЙРБъзМВюКЭЦфЫћЮДжЊаджЪЕФВтСПжЕЃЌЖјЧветвЛЮЪЬтЛсЫцзХШБЪЇаХЯЂЕФдіЖрЖјБфЕУИќМгбЯжиЁЃЕкЖўЃЌбаОПепБиаыМйЩшДцдкШБЪЇжЕЫљдкЕФБфСПгыЦфЫћБфСПДцдкЯпадЙиЯЕЃЌКмЖрЪБКђетжжЙиЯЕЪЧВЛДцдкЕФЁЃ
ЃЈЮхЃЉЖржиЬцДњЗЈ(Multiple Imputation)
ЖржиЙРЫуЪЧгЩRubinЕШШЫгк1987ФъНЈСЂЦ№РДЕФвЛжжЪ§ОнРЉГфКЭЭГМЦЗжЮіЗНЗЈЃЌзїЮЊМђЕЅЙРЫуЕФИФНјВњЮяЁЃЪзЯШЃЌЖржиЙРЫуММЪѕгУвЛЯЕСаПЩФмЕФжЕРДЬцЛЛУПвЛИіШБЪЇжЕЃЌвдЗДгГБЛЬцЛЛЕФШБЪЇЪ§ОнЕФВЛШЗЖЈадЁЃШЛКѓЃЌгУБъзМЕФЭГМЦЗжЮіЙ§ГЬЖдЖрДЮЬцЛЛКѓВњЩњЕФШєИЩИіЪ§ОнМЏНјааЗжЮіЁЃзюКѓЃЌАбРДздгкИїИіЪ§ОнМЏЕФЭГМЦНсЙћНјаазлКЯЃЌЕУЕНзмЬхВЮЪ§ЕФЙРМЦжЕЁЃгЩгкЖржиЙРЫуММЪѕВЂВЛЪЧгУЕЅвЛЕФжЕРДЬцЛЛШБЪЇжЕЃЌЖјЪЧЪдЭМВњЩњШБЪЇжЕЕФвЛИіЫцЛњбљБОЃЌетжжЗНЗЈЗДгГГіСЫгЩгкЪ§ОнШБЪЇЖјЕМжТЕФВЛШЗЖЈадЃЌФмЙЛВњЩњИќМггааЇЕФЭГМЦЭЦЖЯЁЃНсКЯетжжЗНЗЈЃЌбаОПепПЩвдБШНЯШнвзЕиЃЌдкВЛЩсЦњШЮКЮЪ§ОнЕФЧщПіЯТЖдШБЪЇЪ§ОнЕФЮДжЊаджЪНјааЭЦЖЯЁЃNORMЭГМЦШэМўПЩвдНЯЮЊМђБуЕиВйзїИУЗНЗЈЃЈNORMЭГМЦШэМўПЩвддкhttp://www.stat.psu.edu/~jls/misoftwa.htmlПЩвдУтЗбЯТдиЃЉЁЃ
Ш§ЁЂЮхжжВхВЙЗНЗЈЕФЪЕжЄБШНЯ
ЮЊСЫБШНЯетЮхжжШБЪЇжЕВхВЙЗНЗЈЕФВЛЭЌНсЙћЃЌЮвУЧЪЙгУЪЕМЪЪ§ОнПтНјааЪЕжЄбаОПЁЃЪ§ОнРДдДгкСуЕубаОПзЩбЏМЏЭХгк2006ФъЧяЖддЦФЯХЉДх169ЮЛХЉУёНјааЕФОгУёЩњЛюЕїВщЁЃЮвУЧвдДЫДЮЕїВщжаЩцМАЕНЕФ4ИіБфСПЮЊР§ЃКФъСфЁЂЪеШыЁЂОЋЩёЩњЛюТњвтЖШЁЂбЙСІИаЕУЗжЁЃЦфжаЃЌФъСфУЛгаШБЪЇжЕЁЃЪеШывд“ЧЇ”ЮЊЕЅЮЛЃЌга21%ЕФШБЪЇжЕЁЃОЋЩёЩњЛюТњвтЖШЮЊ6ЯюжИБъЕУЗжжЎКЭЃЌзмЗжЮЊ30ЗжЃЌга2%ЕФШБЪЇжЕЁЃбЙСІИаЕУЗжЃЈБОДЮЕїВщЕФвђБфСПЃЉЮЊ3ЯюжИБъЕУЗжжЎКЭЃЌзмЗжЮЊ15ЗжЃЌга16%ЕФШБЪЇжЕЁЃ
ЃЈвЛЃЉУшЪіаджИБъБШНЯ
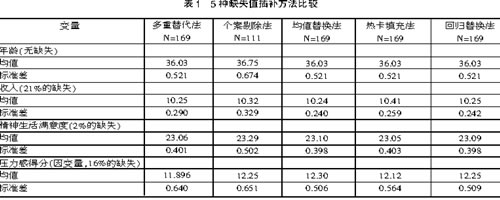
ЮвУЧЪзЯШБШНЯВЩгУ5жжЗНЗЈВхВЙКѓЃЌУПИіБфСПЕФОљжЕКЭБъзМВюЕФБфЛЏЁЃГ§СЫдкИіАИЬоГ§ЗЈжага58ЮЛИіАИБЛЬоГ§жЎЭтЃЌЦфгр4жжЗНЗЈЖМга169ИіИіАИВЮгыМЦЫугыЗжЮіЁЃ
ДгБэ1жаПЩвдЗЂЯжВЩгУВЛЭЌЕФВхВЙЗНЗЈЃЌЦфБфСПЕФОљжЕКЭБъзМВюЪЧВЛЭЌЕФЁЃЕББфСПЕФШБЪЇжЕБШНЯЩйЪБЃЈШчОЋЩёЩњЛюТњвтЖШЃЉЃЌВЩгУ5жжЗНЗЈВхВЙКѓЕФОљжЕКЭБъзМВюВювьНЯаЁЁЃЕЋЕБШБЪЇжЕЫљеМБШР§діДѓЪБЃЈШчЪеШыЁЂбЙСІИаЕУЗжЃЉЃЌВЩгУВЛЭЌЗНЗЈКѓЕФОљжЕКЭБъзМВюВювьНЯДѓЁЃ5жжЗНЗЈжаЃЌЪЙгУИіАИЬоГ§ЗЈКѓИїБфСПЕФБъзМВюЖМУїЯддіДѓЃЌЪЙгУОљжЕЬцЛЛЗЈКѓИїБфСПЕФБъзМВюЖМУїЯдМѕаЁЁЃ
 |
ЃЈЖўЃЉЛиЙщЗжЮіБШНЯ
ЮвУЧвдбЙСІИаЕУЗжЮЊвђБфСПЃЌЦфгр3ИіБфСПЮЊздБфСПНјааЛиЙщЗжЮіЁЃЙлВьБэ2ПЩвдЗЂЯжЃЌДгFжЕЩЯПДЃЌИіАИЬоГ§ЗЈгыЛиЙщЬцЛЛЗЈЕФFжЕНЯИпЁЃ
гЩгкЛиЙщЗжЮіжаЃЌИїИіБфСПЪЧЯрЛЅЙиСЊЕФЃЌЫљвдЫфШЛФъСфБфСПУЛгаШБЪЇжЕЃЌЕЋгЩгкЦфЫћБфСПДцдкШБЪЇЃЌЕМжТФъСфБфСПдкЛиЙщЗНГЬжаЕФЯЕЪ§вВЛсЗЂЩњБфЛЏЁЃДгБэ2жаПЩвдПДГіетжжБфЛЏЪЧБШНЯДѓЕФЃЌЦфжаTжЕДг-0.38БфЛЏжС1.01ЃЌгыжЎЯргІЕФPжЕвВДг0.314БфЛЏжС0.71ЁЃетЬсабЮвУЧЃЌдкНјааЖрдЊЗжЮіЪБЃЌгШЦфвЊзЂжиШБЪЇЪ§ОнВхВЙЗНЗЈЕФЪЙгУЃЌвђЮЊЫќВЛНіЛсгАЯьЕНгаШБЪЇжЕЕФБфСПЃЌЖјЧвгАЯьУЛгаШБЪЇжЕЕФБфСПЁЃ
ВЩгУВЛЭЌВхВЙЗНЗЈЖд“ЪеШы”БфСПЕФгАЯьНЯДѓЁЃЦфжаЃЌЪЙгУШШПЈЬюГфЗЈКѓЕФЯЕЪ§ЪЧзюДѓЕФЃЌВЂЧвУїЯдИпгкСЫВЩгУЦфЫћЗНЗЈВхВЙКѓЕФЯЕЪ§ЁЃДгPжЕЩЯПДЃЌЪЙгУШШПЈЬюГфЗЈИУБфСПЕФгАЯьВЛЪЧЯджјЕФЃЌЕЋЪЙгУЦфЫћВхВЙЗНЗЈЃЌШДПЩвдЪЙЕУИУБфСПЖдвђБфСПЕФгАЯьЪЧЯджјЕФЁЃетКЭЧАУцЕФЗжЮіЪЧвЛжТЕФЃЌМДдкЛиЙщЗжЮіжаЃЌгУШШПЈЬюГфЗЈЛёЕУЕФЯЕЪ§ЪЧВЛЮШЖЈВЛПЩППЕФЁЃ
 |
гІИУЫЕЩЯЪі5жжШБЪЇжЕВхВЙЗНЗЈИїгаРћБзЃЌбаОПепдкбЁгУВхВЙЗНЗЈЪБгІИУзлКЯПМТЧШБЪЇЪ§ОнВњЩњЛњжЦЁЂШБЪЇжЕЫљеМБШР§ЁЂбаОПФмСІЁЂЪБМфЯожЦЕШвђЫиЃЌОпЬхЧщПіОпЬхЗжЮіЃЌбАевЕНдкЕБЧАЬѕМўЯТзюЪЪвЫЕФЗНЗЈЁЃЖдгкИїРрВхВЙЃЌЙВЭЌЕФФПЕФдкгкЪЙВЛЭъШЋбљБОЕФвбгааХЯЂЕУЕНзюМбРћгУЁЃ